
机器学习
Linear regression
Supervised Learning
Given the ‘right answer’ for each example in the data
Regression Learning
Predict real-valued output
Definition
给定数据集D={(x1, y1), (x2, y2), … },从此数据集中学习得到一个线性模型,这个模型尽可能准确地反应x(i)和y(i)的对应关系。这里的线性模型,就是属性(x)的线性组合的函数,可表示为 $$ f(x) = w_0 + w_1x_1 + w_2x_2 +…+ w_nx_n $$ 向量表示为 $$ f(x) = w^Tx $$ x = (x0;x1;x2….;xn) x0=1
w = (w0;w1;w2;…;wn) 列向量,以 ; 为分隔
w表示weight,权重,表示对应的属性在预测结果中的权重
Cost function
为了得到线性回归的函数,需要求出权重,设立的指标是差的平方和,为了得到拟合程度最高的线性函数,因此需使下式取最小值来得到期望的权重 $$ J(w) = \frac{1}{2m}\sum_{i=1}^m(f(x_i)-y_i)^2 $$ 这个函数称为代价函数 cost function
2m的2是为了抵消求偏导后多出来的2,便于计算,对于结果无影响
Gradient Descent
- 为 w 赋某个值,作为起始值
- 不断改变 w 来减小代价函数,直到极小值为止
Gradient Descent Algorithm
$$ w_j = w_j - \alpha\frac{\partial}{\partial w_j}J(w)\quad $$
- α表示learning rate,控制梯度下降的速度
- j 从 0 取到 m,每次梯度下降同时更新整个 w (先计算出所有的wj,再进行赋值)
- 随着梯度下降的进行,导数的值会变小,因此梯度下降会自动减小步长,因此不需减小α
Feature Scaling
Get every feature into approximately a -1<=xi<=1 range
Mean normalization
用(xi-μi)/si代替xi
- μi 为xi的平均值
- si 有两种取法
- xi 的范围,max - min
- xi 的标准差
Linear Regression Algorithm
初始化 w
建立损失函数 cost function
对所有wj求偏导数,并进行梯度下降
xi 为第 i 组 x 的值,xij表示wj在第 i 组对应的x的值
$$ \frac{\partial}{\partial w_j}J(w) = \frac{1}{m}\sum_{i=1}^m[(f(x_i)-y_i)x_{ij}] $$
Normal Equation
求 w 的解析解法, 一步求得最优解
原理:当导数为0时,得到的值代入原函数可以求得极值
下式为 w 的最优解
- X 为m×n+1的矩阵,每一行是一组x的取值,其中x0恒取1
- y 为长度m的列矩阵
$$ w = (X^TX)^{-1}X^Ty $$
Classification
Logistic function
$$ g(z)=\frac{1}{1+e^{-z}} $$
Decision boundary
能够把样本正确分类的一条边界,主要有线性决策边界(linear decision boundaries)和非线性决策边界(non-linear decision boundaries)
决策边界是假设函数的属性,由参数决定 $$ f(x) = g(w^Tx)=\frac{1}{1+e^{-w^Tx}} $$
Cost function
$$ Cost(f(x),y) = \left{\begin{aligned} -log(f(x)) && y=1\ -log(1-f(x)) && y=0 \ \end{aligned}\right. $$


Gradient Descent
$$ w_j = w_j - \alpha\frac{\partial}{\partial w_j}J(w) $$
$$ \frac{\partial}{\partial w_j}J(w) = \frac{1}{m}\sum_{i=1}^m[(f(x_i)-y_i)x_{ij}] $$
Multi-class classification
假设有3个类别A,B,C进行分类,则通过将A看作正类,BC看作负类,转化为二分类问题,然后分别将B,C看作正类,进行同样的操作,构造出三个二分类器,对一某一类,选择三个二分类器中,概率最高的一类即可
Overfitting
过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差
Addressing
- 减少特征变量
- Regularization
- 保留所有特征变量,但是减少量级以及w的大小
Regularization
在现有Features不变情况下,降低部分不重要Features的影响力,从而防止过拟合
在代价函数后加一个惩罚项,来对某些参数作出限制
Regularized linear regression
注:正则化项仅在训练时使用,计算误差时不使用
Cost function
$$ J(w) = \frac{1}{2m}[\sum_{i=1}^m(f(x_i)-y_i)^2 + \lambda\sum_{j=1}^nw_j^2] $$
Gradient descent
$$ w_j = w_j - \alpha\frac{1}{m}[\sum_{i=1}^m(f(x_i)-y_i)x_{ij}+\frac{\lambda}{m}w_j] $$
$$ w_j = w_j(1-\alpha\frac{\lambda}{m}) - \alpha\frac{1}{m}\sum_{i=1}^m(f(x_i)-y_i)x_{ij} $$
Normal equation
$$ w = (X^TX+\lambda L)^{-1}X^Ty $$
L为(n+1)×(n+1)的对角矩阵,其主对角线第一个元素为0,其余为1
Regularized logistic regression
Cost function
$$ J(w)=\frac{1}{m}\sum^m_{i=1}(-ylog(f(x))-(1-y)log(1-f(x)))+\frac{\lambda}{2m}\sum_{j=1}^nw_j^2 $$
Gradient descent
$$ w_j = w_j - \alpha[\frac{1}{m}\sum_{i=1}^m(f(x_i)-y_i)x_{ij}+\frac{\lambda}{m}w_j] $$
Neural Networks

Layer1 输入层 input
Layer2 隐藏层 hidden
可以有多个隐藏层
Layer3 输出层 output
单层,但可以有多个神经元
Forward propagation
- 用 ai(l) 表示第 l 层中第 i 个神经元的输出,该层中的 n 个神经元可以用向量 a(l) 表示
$$ a^{(l)}=\left[\begin{array}{c} a_1^{(l)} \ a_2^{(l)} \ \vdots \ a_n^{(l)} \end{array}\right] $$
- 用 W(l) 表示第 l 层 与 第 l+1 层之间的传播参数,其中m为第 l+1 层的单元数量,n为第 l 层的单元数量
$$ W^{(l)}=\left[\begin{array}{cccc} W_{11}^{(l)} & W_{12}^{(l)} & \ldots & W_{1 n}^{(l)} \ W_{21}^{(l)} & W_{22}^{(l)} & \ldots & W_{2 n}^{(l)} \ \vdots & \vdots & \vdots & \vdots \ W_{m 1}^{(l)} & W_{m 2}^{(l)} & \ldots & W_{m n}^{(l)} \end{array}\right] $$
- 用 zi(l+1) 表示第 l+1 层中第 i 个单元的加权输入总和
$$ z_i^{(l+1)}=\sum_{j=1}^n W_{i j}^{(l)} a_j^{(l)} $$
- 经过激活函数得到第 l+1 层的输入
$$ a^{(l+1)}=g\left(z^{(l+1)}\right) $$
Bias
偏差项相当于为向量 a(l) 加上 a0(l) 其值为1(相当于常数项),输出值会随 W0(l) 的改变而改变,从而实现偏差的效果
当没有偏差项时,W 只能改变函数的陡峭程度,而不能进行平移,从而无法很好的提高准确性
Activation function
激活函数是向神经网络中引入非线性因素,通过激活函数神经网络就可以拟合各种曲线
logistic function 就是一种激活函数
Cost function
Logistic regression: $$ J(\theta)=-\frac{1}{m}\left[\sum_{i=1}^m y^{(i)} \log h_\theta\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_\theta\left(x^{(i)}\right)\right)\right]+\frac{\lambda}{2 m} \sum_{j=1}^n \theta_j^2 $$ Neural network:
代价函数与逻辑回归的代价函数相似,只不过此处处理的是K分类问题,因此计算时需要考虑K个输出单元之和 $$ \begin{aligned} J(\Theta)=&-\frac{1}{m}\left[\sum_{i=1}^m \sum_{k=1}^K y_k^{(i)} \log \left(h_{\Theta}\left(x^{(i)}\right)\right)k+\left(1-y_k^{(i)}\right) \log \left(1-\left(h{\Theta}\left(x^{(i)}\right)\right)k\right)\right] +\frac{\lambda}{2 m} \sum{l=1}^{L-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{l+1}}\left(\Theta_{j i}^{(l)}\right)^2 \end{aligned} $$
Backpropagation
反向传播算法,从输出层开始计算误差,然后返回到上一层计算误差,直至计算到第二层的误差(不需要考虑输入层的误差),相当于不断将误差反向传递
作用:计算神经网络每一层中代价函数的偏导数
δ(l) j表示第 l 层,第 j 个结点的误差
- 计算输出层的误差
$$ \delta_j^{(l)}=a_j^{(l)}-y_j $$
- 反向传播,计算前面每一层(除了输入层)的误差
$$ \delta^{(l)}=\delta^{(l)}+(\theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)}) $$
$$ \delta^{(l)}=\delta^{(l)}+\delta^{(l+1)}(a^{(l)})^T $$
处理正则项,当j = 0时不加正则项 $$ D^{(l)}{ij}=\frac{1}{m}\delta^{(l)}{ij} + \lambda\theta^{(l)}_{ij} $$
计算偏导数
$$ \frac{\partial}{\partial\theta^{(l)}{ij}}J(\theta) = D^{(l)}{ij} $$
Gradient checking
比较 数值方法求得的梯度 和 算法求得的梯度,确保实现的反向传播误差在一定范围之内
作用:实现反向传播后,有时反向传播并不完全正确,使用梯度检验来确保反向传播的正确性
注:算法效率很低,在进行训练之前需要关闭梯度检验 $$ \frac{\partial}{\partial\theta}J(\theta)\approx\frac{J(\theta+\epsilon)-J(\theta-\epsilon)}{2\epsilon} $$
$$ \frac{\partial}{\partial\theta_i}J(\theta)\approx\frac{J(\theta_1,…\theta_i+\epsilon,…)-J(\theta_1,…\theta_i-\epsilon,…)}{2\epsilon} $$
Random Initialization
对于一个神经网络,若将 θ 全部初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响,每次迭代后同样的表达式结果仍然是相同的,即隐含单元永远是对称的。此时,无论进行多少次梯度下降,永远计算的是同一个函数,梯度下降失效
随机初始化:将每一个 θ 初始化为 [-ε, ε] 的随机值 $$ \theta = rand(row,column).*(2\epsilon)-\epsilon $$ 注:此处的 ε 与梯度检验中的无关
Overall process
- 选择神经网络结构,即神经元之间的连接模式
- input units:特征的维度
- output units:类别的数量
- hidden layer:默认情况下,只有1层,且大于1层时,每层单元数量相同
- 随机初始化权重
- 执行前向传播计算得到输出
- 计算代价函数
- 反向传播计算偏导数
- 梯度检查确保反向传播的正确性
- 检查完后,需要停止梯度检查
- 使用优化算法(如梯度下降)最小化代价函数
Advice for applying Machine Learning
Evaluation
Linear regression $$ J_{test}(\theta)=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(f(x^{(i)})-y^{(i)})^2 $$
logistic regression $$ J_{test}(\theta)=-\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}y^{(i)}logf(x^{(i)})+(1-y^{(i)})logf(x^{(i)}) $$
Misclassification error $$ error(f(x),y)=\left{\begin{aligned} 1 && y=0andf(x)\geq0.5\ 1 && y=1andf(x)<0.5\ 0 && otherwise \ \end{aligned}\right. $$
$$ Test error = \frac{1}{m_{test}}\sum_{i=1}^{m_{test}}error(f(x^{(i)},y^{(i)}) $$
Model selection
在机器学习中,通常不把所有数据用作训练集,若仅分为训练集和测试集,最终模型与参数的选取将极大程度依赖于对训练集和测试集的划分方法
因此,一般分为三个数据集
训练集 Training set 60%
用来训练模型,即确定模型的权重和偏置这些参数
交叉验证集 Cross Validation set 20%
用于模型的选择,更具体地来说,验证集并不参与学习参数的确定,也就是验证集并没有参与梯度下降的过程。验证集只是为了选择超参数,比如网络层数、网络节点数、迭代次数、学习率这些都叫超参数
测试集 Test set 20%
测试集只使用一次,即在训练完成后评价最终的模型时使用,仅仅使用于模型的评价。
如果用测试集来进行模型一些参数的调整选择,则最终得到的模型可能不适用于数据集以外的数据
Diagnosing bias and variance


Bias(underfit)
训练集和交叉验证集误差都很大
Variance(overfit)
训练集误差很小,交叉验证集误差很大
Regularization

λ过大
高次项的重要性被降低,代价函数趋于低次项,出现欠拟合,偏差bias过大
训练集误差大,验证集误差大
λ过小
高次项的重要性提高,代价函数趋于高次项,出现过拟合,方差variance过大
训练集误差小,验证集误差大
λ的选取:单独考虑0,然后从0.01开始,以两倍的步长放大,直到一个比较大的值,从而得到一组λ的值
然后用交叉验证集,和评价variance一样的方式评价λ,从而选取一个合适的λ
Learning curves
作用:判断学习算法是否有偏差和方差的问题
学习曲线为 训练误差 和 验证误差 随样本数量变化的曲线
随着数据量的增多,训练集的误差开始变大,但是泛化的效果更好,验证集的误差变小
以下为不同偏差和方差情况下的学习曲线:
高偏差时,由于参数很少,随着训练集增大,训练误差和验证误差都很大,且趋于相等
同时,高偏差情况下,随着训练集数据的增多,验证集的误差不会再明显下降
高方差时,训练集和验证集的误差会有较大差距
同时,高方差的情况下,随着训练集数据的增多,验证集误差会下降
Debugging a learning algorithm
- 高方差
- 获取更多训练数据
- 减少特征数量
- 增大λ
- 高偏差
- 增加特征数量
- 增加多项式特征数量
- 减小λ
System design
Error analysis
Error metrics for skewed class
skewed class
偏斜类,正样本和负样本得数量相差极大
训练得到得模型错误率只有1%,但令y = 0(或y=1)得到的错误率可能只有0.5%
Error metrics
对于偏斜类的模型,分类的精确度可能很高,但并不能判断模型的质量
例如:对于y=0(或y=1)这样的模型,精确度虽然很高,但显然它不是一个好的模型
因此,我们需要一个指标来判断模型的质量
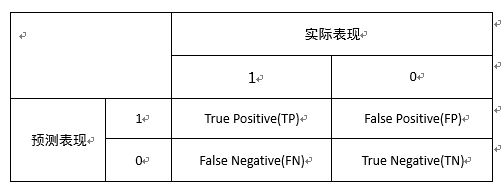
Precision 准确率
在预测阳性的人中,有多少人是真正阳性
TP/(TP+FP)
Recall 召回率
在阳性的人中,有多少人被正确预测为阳性
TP/(TP+FN)
Trade off precision and recall
对于偏斜类的分类,不同于以往的二分类,因为出现某一类别的概率极低,因此只有在非常肯定的情况下,才会将样本归于低概率类,所以此处通过修改判断的临界值(之前的二分类是0.5)来实现,从而提高Precision,但这个方法同时会降低Recall。
相对的,如果想要提高Recall,可以使用较低的临界值,但同时会降低Precision
选取临界值的方法是 F Score , 考虑P和R的平均值的同时,给予P和R中较低的值更高的权重 $$ FScore=2\frac{PR}{P+R} $$
Support Vector Machines
支持向量机,与logistic regression不同,它会直接输出预测结果,而不是概率
Optimization Objective
logistic regression $$ J(w)=\frac{1}{m}\sum^m_{i=1}(y(-log(f(x)))+(1-y)(-log(1-f(x))))+\frac{\lambda}{2m}\sum_{j=1}^n\theta^2_j $$ support vector machines $$ J(w)=C\sum^m_{i=1}(ycost_1(\theta^Tx))+(1-y)cost_0(\theta^Tx))+\frac{1}{2}\sum_{j=1}^n\theta^2_j $$
Large margin classifier
支持向量机训练得到的模型,与训练样本的最小距离(margin)会更大一些,即将正负样本以最大的间距分开
mathematics
向量相乘的内积
有向量u,v. p是向量v 在 u上投影的长度 $$ ||u||=\sqrt{u_1^2+u_2^2} $$
$$ u^Tv =v^Tu=p||u||=u_1v_1+u_2v_2 $$
权重调整
不考虑θ0,即θ0取0
正则化项
正则化项可以转化为权重的范数
若要减小代价函数,需要减小权重θ的向量长度
$$ min\frac{1}{2}\sum_{j=1}^n\theta^2_j=\frac{1}{2}(\theta^2_1+\theta^2_2)=\frac{1}{2}\sqrt{(\theta^2_1+\theta^2_2)}^2=\frac{1}{2}||\theta||^2 $$
- 代价函数
$$ \theta^Tx^{(i)}\geq1(y^{(i)}=1) $$
$$ \theta^Tx^{(i)}\leq-1(y^{(i)}=0) $$
p为向量x在权重向量θ上的投影
当p较小时,为了满足代价函数,θ的长度会取一个较大值
而当p较大时,θ才可以减小
因此支持向量机训练的模型会是一个大边距分类器 $$ \theta^Tx^{(i)}=p^{(i)}||\theta|| $$
Kernel
当需要构造非线性决定边界时,需要加入高次的特征,从前面可以知道,加入高次特征时,计算量会呈几何式的增长,计算量过大,因此需要一个更好的方法来训练复杂的非线性边界
Idea
f 为相似度,此处的相似度函数k即为核函数(kernel function),此例使用的实际的核函数为高斯函数
l(i)为特征点的一个点对
计算出的结果为 l(i) 与x的相似度,实际计算时,会选取若干个l点对 $$ f_i = k(x,l^{(i)}) = exp(-\frac{||x-l^{(i)}||^2}{2\sigma^2}) $$ 通过使用 f 来代替 x 进行训练,从而将特征x映射到l,训练出更加复杂的模型 $$ J(w)=C\sum^m_{i=1}(y^{(i)}cost_1(\theta^Tf^{(i)}))+(1-y^{(i)})cost_0(\theta^Tf^{(i)}))+\frac{1}{2}\sum_{j=1}^\bold m\theta^2_j $$
Other available kernels
Polynomial kernel
包含两个参数,次数和常数 $$ k(x,l)=(x^Tl)^2 $$
$$ k(x,l)=(x^Tl+constant)^{degree} $$
String kernel
chi-square kernel
histogram intersection kernel
Choose landmarks
在实际应用时,需要足够多的标记点对l,可以直接选取训练集中的样本点相同位置的点作为标记点,即将训练集中的样本点直接作为标记点使用 $$ l^{(i)}=x^{(i)} $$
$$ f_i = k(x,l^{(i)}) $$
Choose parameters
C = 1/λ
C过大
低偏差,高方差
C过小
高偏差,低方差
σ
σ过大
高偏差,低方差
σ过小
低偏差,高方差
Mercer’s Theorem
并不是所有的核函数都可以使用,需要用默塞尔定理来验证核函数是否可以使用
定理:任何半正定的函数都可以作为核函数。
对于半正定的函数f(xi,xj),是指拥有训练数据集合(x1,x2,…xn),我们定义一个矩阵的元素aij = f(xi,xj),这个矩阵大小为n×n,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数
给定一个大小为 n×n 的实对称矩阵 A ,若对于任意长度为 n 的非零向量 X,有 XTAX≥0 恒成立,则矩阵 A 是一个半正定矩阵
K-Means algorithm
K均值算法是一种无监督学习算法,训练集无标签,需要算法根据数据特征来分为不同的簇
假设有一个无标签的数据集,并且想将其分为两个簇,使用K均值算法,具体操作如下
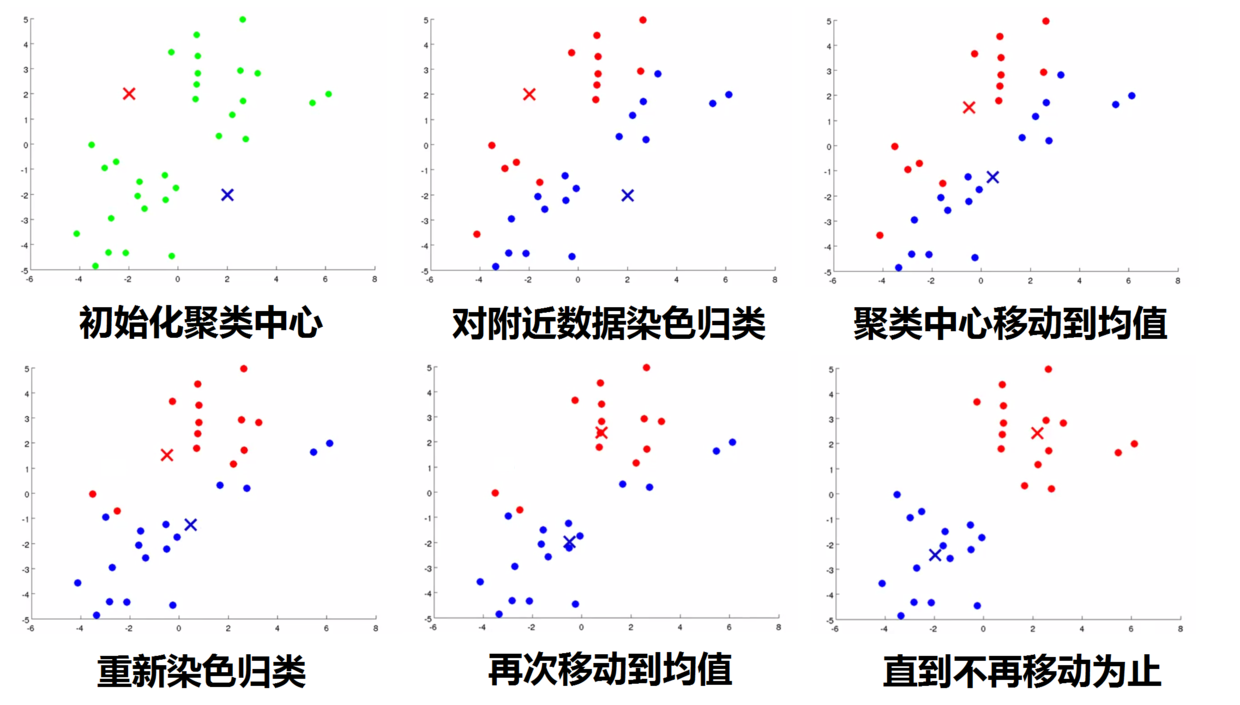
随机生成两点(或k个点),作为聚类中心
分配数据点
根据每个点与聚类中心距离的远近,将数据点分配给较近的聚类中心
移动聚类中心
将聚类中心移动到上一步分配的点的均值处
反复执行(2)(3)步骤,直到不在移动为止
Optimization objective
c(i)是样本x(i)当前被分配的聚类的索引(1,2…,K)
μk是第k个聚类中心的位置
μc(i)是x(i)所属的簇的聚类中心
代价函数为 样本x与所对应聚类中心的距离 $$ J(c^{(1)},…,c^{(m)},\mu_1,…,\mu_K)=\frac{1}{m}\sum_{i=1}^m||x^{(i)}-\mu_{c^{(i)}}||^2 $$
Randomly initialize
随机初始化聚类中心,随机选取K个点,作为K个聚类中心的初始点即可,为了避免结果收敛于局部最优解而非全局最优解,需要进行多次(50-1000)随机初始化,并进行多次运算,最后根据代价函数的结果来选取结果
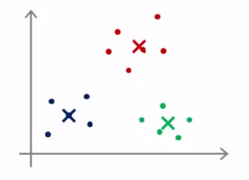
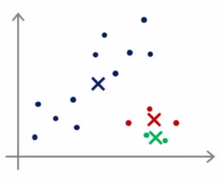
Choosing the number of clusters
选取聚类的数量
Elbow method
画出代价函数随K的变化曲线,选取拐点处的聚类数量即可,但这种方法不适用于所有问题
- 根据目的来选择
Dimensionality Reduction
降维,将原始高维特征空间中的点向一个低维空间投影,移除原特征集属性之间的相关性与冗余性
Motivation
Data compression
压缩数据,减少数据的特征,从而减少计算量,加快算法
Data visualization
数据可视化,降不可可视化的多维数据降至二维,从而便于可视化观察特征
Principal Component Analysis problem formulation
主成分分析(PCA)法
先考虑将数据从二维降到一维,则需要找到一个向量,将数据投影到该向量的距离之和最小
如果想将数据从n维降到k维,这种情况下,我们需要找k个方向来对数据进行投影,需要使数据点到投影点的距离之和最小
数据预处理
执行均值标准化 $$ x_j = \frac{x_j-\mu_j}{s_j} $$
计算协方差矩阵Σ $$ \Sigma=\frac{1}{m}\sum_{i=1}^n(x^{(i)})(x^{(i)})^T $$
奇异化分解
[U,S,V] = svd(Σ)U:A的奇异向量组成的矩阵,AA’的正交单位特征向量组成U。 S:对角矩阵,对角元素是A的奇异值,非负且按降序排列。 V:A的奇异向量组成的矩阵,A’A的正交单位特征向量组成V。
获得降维矩阵
取U(n×n)的前k列,作为降维矩阵Ureduce(n×k)
计算投影点
$$ z = U_{reduce}^Tx $$
Reconstruction from compressed representation
$$ x_{approx} = U_{reduce}z $$
把降维的数据还原为高维数据(会有损失)
Choosing the number of Principal Components
平均平方投影误差 $$ \frac{1}{m}\sum_{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2 $$ 数据总方差 $$ \frac{1}{m}\sum_{i=1}^m||x^{(i)}||^2 $$ 选择满足下列不等式的最小值k,使降维后的数据量能保留原数据的99%以上的方差特性 $$ \frac{\frac{1}{m}\sum_{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2}{\frac{1}{m}\sum_{i=1}^m||x^{(i)}||^2}\leq0.01 $$ 上述式子可以利用奇异值分解中得到的S来计算 $$ 1-\frac{\sum_{i=1}^kS_{ii}}{\sum_{i=1}^nS_{ii}} $$
Anomaly detection
异常检测,适用于拥有一个偏斜数据集,异常样本的数目远小于正常样本
同时,当异常类型不一,很难根据现有的异常样本拟合判断异常样本的形态
Gaussian distribution
高斯分布 $$ P(x)=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2}) $$
Algorithm
异常检测算法
选择用于异常检测的特征
参数拟合
得到每一个特征对应的高斯分布 $$ \mu_j=\frac{1}{m}\sum_{i=1}^mx_j^{(i)} $$
$$ \sigma_j^2=\frac{1}{m}\sum_{i=1}^m(x_j^{(i)}-\mu_j)^2 $$
异常检测函数 $$ p(x)=\Pi_{j=1}^np(x_j;\mu_j,\sigma_j^2) $$
异常检测
Anomaly if p(x) < ε
Evaluation
异常检测算法的构造中,使用的是无监督学习,数据集都不带标签,而在评估异常检测算法是否正常运行的过程中,使用带标签的测试集
数据集的划分
正常数据集按照6 2 2的比例分为训练集,验证集和测试集(y=0)
异常数据集按照1:1的比例放入验证集和测试集中(y=1)
模型训练
使用训练集拟合模型p(x)
选择评价指标
由于异常样本很少,因此这是一个倾斜类,使用之前的倾斜类的评估指标即可
选择ε
使用验证集,通过评价指标的表现情况来选择ε
使用测试集评价
Multivariate Gaussian distribution
当对每个特征分别构造高斯分布时,会忽略特征之间的相关性
因此当特征相关性较强时,不在对每个特征分别构造高斯分布,而是建立一个整体的高斯分布模型,自动捕捉特征之间的相关性 $$ p(x;\mu,\Sigma)=\frac{1}{(2\pi)^\frac{n}{2}|\Sigma|^\frac{1}{2}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)) $$
μ 特征的均值,为 n × 1 的向量 $$ \mu=\frac{1}{m}\sum_{i=1}^mx^{(i)} $$
Σ 特征的协方差,为 n × n 的矩阵 $$ \Sigma = \frac{1}{m}\sum_{i=1}^m(x^{(i)}-\mu)(x^{(i)}-\mu)^T $$
Collaborative filtering
协同过滤,用于构建推荐系统
通过群体的行为来找到某种相似性(用户之间的相似性或目的物之间的相似性),通过该相似性来为用户做决策和推荐
r(i,j)
如果用户 j 为电影 i 打分了 则为1 否则为0
y(i,j)
用户 j 为电影 i 打分的分数
θ(j)
用户 j 的参数向量
x(i)
电影 i 的特征向量
(θ(j))T(x(i))
预测用户 j 为电影 i 的评分
m(j)
用户 j 评价的电影的数量
Optimization objective
To learn θ(j) $$ min_{\theta^{(j)}}\frac{1}{2}\sum_{i:r(i,j)=1}((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{k=1}^n(\theta_k^{(j)})^2 $$ To learn all θ $$ min_{\theta^{(1)}…\theta^{(j)}}\frac{1}{2}\sum_{j=1}^{n_u}\sum_{i:r(i,j)=1}((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(\theta_k^{(j)})^2 $$ Gradient descent update $$ \theta_{k}^{(j)}:=\theta_{k}^{(j)}-\alpha \sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right) x_{k}^{(i)}(\text { for } k=0) $$
$$ \theta_{k}^{(j)}:=\theta_{k}^{(j)}-\alpha\left(\sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right) x_{k}^{(i)}+\lambda \theta_{k}^{(j)}\right)(\text { for } k \neq 0) $$
Given θ to learn x $$ min_{x^{(i)}}\frac{1}{2}\sum_{i:r(i,j)=1}((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{k=1}^n(x_k^{(i)})^2 $$
$$ min_{x^{(1)}…x^{(i)}}\frac{1}{2}\sum_{j=1}^{n_m}\sum_{i:r(i,j)=1}((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_m}\sum_{k=1}^n(x_k^{(i)})^2 $$
Minimizing x and θ simultaneously $$ J(x^{(1)},…x^{(n_m)},\theta^{(1)}…\theta^{(n_u)})=\frac{1}{2}\sum_{(i,j):r(i,j)=1}((\theta^{(j)})^T(x^{(i)})-y^{(i,j)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(x_k^{(i)})^2+\frac{\lambda}{2}\sum_{j=1}^{n_u}\sum_{k=1}^n(\theta_k^{(j)})^2 $$ Gradient descent $$ x_{k}^{(i)}:=x_{k}^{(i)}-\alpha\left(\sum_{j: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right) \theta_{k}^{(j)}+\lambda x_{k}^{(i)}\right) $$
$$ \theta_{k}^{(j)}:=\theta_{k}^{(j)}-\alpha\left(\sum_{i: r(i, j)=1}\left(\left(\theta^{(j)}\right)^{T} x^{(i)}-y^{(i, j)}\right) x_{k}^{(i)}+\lambda \theta_{k}^{(j)}\right) $$
Find related movies
对于每个电影 i ,已经学习到了特征向量 x(i)
衡量两个电影的相关性使用他们特征向量的距离,距离越小,相关性越强,推荐距离最小,即相关性最强的几个即可 $$ ||x^{(i)}-x^{(j)}|| $$
Mean normalization
均值归一化
计算出每个电影的平均分数,然后将每个人对每个电影的评分都减去平均分数,使得平均值为0
可以避免当一个新用户出现时,预测新用户对任何电影的评分都为0
Large datasets
Stochastic gradient descent
随机梯度下降,将算法应用于更大的训练集中
随机打乱所有数据
重复进行梯度下降 $$ \theta_j =\theta_j-\alpha(f(x^{(i)})-y^{(i)})x^{(i)}_{j} $$
$$ cost(\theta,(x^{(i)},y^{(i)}))=\frac{1}{2}(f(x^{(i)})-y^{(i)})^2 $$
$$ \frac{\partial}{\partial\theta_j}cost(\theta,(x^{(i)},y^{(i)}))=(f(x^{(i)})-y^{(i)})x^{(i)}_{j} $$
随机梯度下降不需要对全部样本求和来得到梯度
之前是求代价函数 J 的偏导数,此处是求θj的代价cost的导数
Convergence
检查梯度下降是否收敛
每1000次迭代,画出这1000个样本的cost(θ,x,y)的平均值
Mini-batch gradient descent
批量梯度下降,每次迭代使用全部样本;随机梯度下降,每次迭代使用1个样本;而Mini-batch梯度下降介于两者之间,每次迭代下降使用b个样本 $$ \theta_j =\theta_j-\alpha\frac{1}{b}\sum_{k=i}^{i+b-1}(f(x^{(k)})-y^{(k)})x^{(k)}_{j} $$
Map-Reduce approach
数据集过大,不在一台计算机上跑所有数据时,可以使用映射减少与数据并行
将数据集分成k个子集
用k台计算机计算时,可以平均分为k份
计算每个子集 $$ temp^{(k)}j=\sum{i=(100k-99)}^{100k}(f(x^{(i)})-y^{(i)})x^{(i)}_j $$
汇总计算结果 $$ \theta_j = \theta_j-\alpha\frac{1}{m}\sum_{i=1}^{k}temp_j^{(i)} $$