
算法
排序
选择排序
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
public int[] sort(int[] sourceArray) throws Exception {
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 总共要经过 N-1 轮比较
for (int i = 0; i < arr.length - 1; i++) {
int min = i;
// 每轮需要比较的次数 N-i
for (int j = i + 1; j < arr.length; j++) {
if (arr[j] < arr[min]) {
// 记录目前能找到的最小值元素的下标
min = j;
}
}
// 将找到的最小值和i位置所在的值进行交换
if (i != min) {
int tmp = arr[i];
arr[i] = arr[min];
arr[min] = tmp;
}
}
return arr;
}
冒泡排序 - Bubble Sort
两两比较相邻记录的关键字,如果反序则交换,直到没有反序的记录为止
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
for (int i = 1; i < arr.length; i++) {
// 设定一个标记,若为true,则表示此次循环没有进行交换,也就是待排序列已经有序,排序已经完成。
boolean flag = true;
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
if (flag) {
break;
}
}
return arr;
}
插入排序
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)

public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
// 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的
for (int i = 1; i < arr.length; i++) {
// 记录要插入的数据
int tmp = arr[i];
// 从已经排序的序列最右边的开始比较,找到比其小的数
int j = i;
while (j > 0 && tmp < arr[j - 1]) {
arr[j] = arr[j - 1];
j--;
}
// 存在比其小的数,插入
if (j != i) {
arr[j] = tmp;
}
}
return arr;
}
归并排序
算法步骤
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
重复步骤 3 直到某一指针达到序列尾;
将另一序列剩下的所有元素直接复制到合并序列尾。 ####代码实现 public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
if (arr.length < 2) { return arr; } int middle = (int) Math.floor(arr.length / 2); int[] left = Arrays.copyOfRange(arr, 0, middle); int[] right = Arrays.copyOfRange(arr, middle, arr.length); return merge(sort(left), sort(right));}
protected int[] merge(int[] left, int[] right) { int[] result = new int[left.length + right.length]; int i = 0; while (left.length > 0 && right.length > 0) { if (left[0] <= right[0]) { result[i++] = left[0]; left = Arrays.copyOfRange(left, 1, left.length); } else { result[i++] = right[0]; right = Arrays.copyOfRange(right, 1, right.length); } }
while (left.length > 0) { result[i++] = left[0]; left = Arrays.copyOfRange(left, 1, left.length); } while (right.length > 0) { result[i++] = right[0]; right = Arrays.copyOfRange(right, 1, right.length); } return result;
}
希尔排序
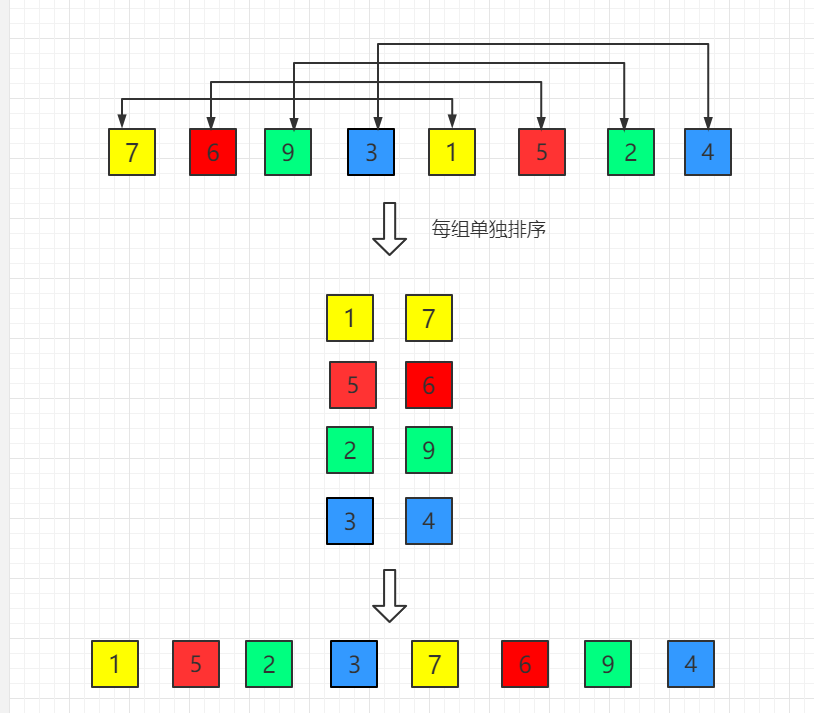
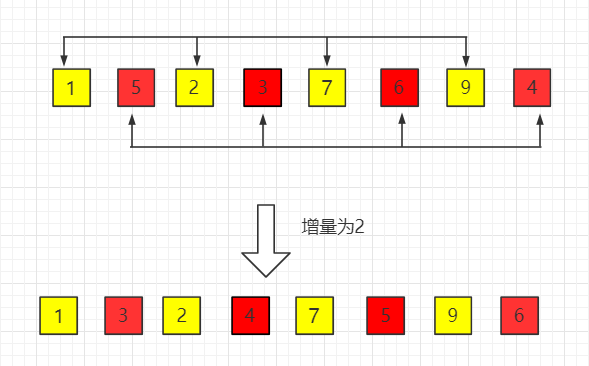
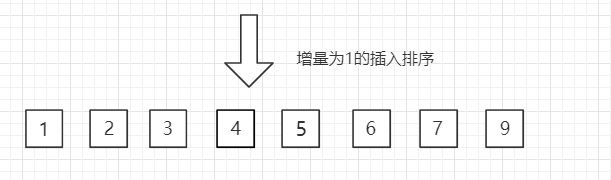
代码实现
public static void shellSort(int[] arr) { int length = arr.length; int temp; for (int step = length / 2; step >= 1; step /= 2) { for (int i = step; i < length; i++) { temp = arr[i]; int j = i - step; while (j >= 0 && arr[j] > temp) { arr[j + step] = arr[j]; j -= step; } arr[j + step] = temp; } } }
快速排序
算法步骤
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
代码实现
public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
return quickSort(arr, 0, arr.length - 1);
}
private int[] quickSort(int[] arr, int left, int right) { if (left < right) { int partitionIndex = partition(arr, left, right); quickSort(arr, left, partitionIndex - 1); quickSort(arr, partitionIndex + 1, right); } return arr; }
private int partition(int[] arr, int left, int right) { // 设定基准值(pivot) int pivot = left; int index = pivot + 1; for (int i = index; i <= right; i++) { if (arr[i] < arr[pivot]) { swap(arr, i, index); index++; } } swap(arr, pivot, index - 1); return index - 1; }
private void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; }
线性表
队列
先进先出,将首个元素置于最后,直接head++,tail++
栈 - stack
栈是仅在表尾进行插入和删除操作的线性表,允许插入和删除操作的一端称为栈顶(top),另一端称为栈底(bottom),栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构
顺序存储结构实现
typedef int ElemType; typedef struct{ ElemType data[MAXSIZE]; int top; }Stack;
// 进栈操作push
bool push(Stack *s,ElemType e){
// 栈满
if(s->top == MAXSIZE-1){
return false;
}
s->top++;
s->data[s->top] = e;
return true;
}
// 出栈操作pop,返回出栈的数据
ElemType pop(Stack *s){
// 栈空
if(s->top == -1){
return false;
}
ElemType temp = s->data[s->top];
s->top--;
return temp;
}
链式存储结构实现
typedef struct stackNode{ ElemType data; struct stackNode* next; }StackNode,*LinkStackPtr;
typedef struct LinkStack{
LinkStackPtr top;
int count;
}LinkStack;
bool push(LinkStack *s,ElemType e){
// 创建新的一个结点
LinkStackPtr node = (LinkStackPtr)malloc(sizeof(StackNode));
node->data = e;
// 将新的结点置于栈顶
node->next = s->top;
s->top = node;
s->count++;
return true;
}
ElemType pop(LinkStack *s){
LinkStackPtr p;
if(s.isEmpty()){
return null;
}
ElemType temp = s->top->data;
p = s->top;
s->top = s->top->next;
free(p);
s->count--;
return temp;
}
链表
用一个含有value和next指针的结构体,定义一个结构体数组,连接一串数字
struct node{
int value;
struct node* next;
};
struct node *head;
head = NULL;
// 动态申请空间,存放节点,并让临时指针p指向此空间
struct node *p;
p = (struct node*)malloc(sizeof(struct node));
p->value = number;
p->next = NULL;
// head需要指向第一个节点
if(head == NULL)
head = p;
else
q->next = p;
q = p;
// 若p不是第一个节点,则上一个节点的next指向p
// 输出链表中所有数
struct node *t;
t = head;
while(t!=NULL){
printf("%d ",t->value);
t = t->next;
}
模拟链表
两个数组,一个data存放数据,一个data记录存放序列中该数右边的数
//输出链表中所有的数
t=1;
while(t!=0)
{
printf("%d ",data[t]);
t=right[t];
}
###堆
###并查集
// 初始化
int fa[MAXN];
void init(int n){
for(int i = 1;i<=n;i++) fa[i] = i;
}
// 查询,寻找i的祖先并返回
int find(int i){
if (fa[i] != i) // 判断节点是否是祖先
// 路径压缩 使该点的父亲等于父亲的祖先
fa[i] = find(fa[i]);
return fa[i];
}
// 合并
void union(int i,int j){
fa[find(i)] = find(j);
}
树
术语
- 结点的度:一个结点拥有子树的数目
- 树的度:结点度的最大值
- 叶子结点:没有子树(度为0)的结点,也称终端结点
- 分支结点:度不为0的结点
- 结点的层次:根节点为第1层,根节点的子节点为第2层,以此类推
- 树的深度:结点层次的最大值
- 有序树:子树有先后次序
- 无序树:子树无先后次序
树的存储结构
1. 父结点表示法
每个结点的父结点唯一,因此设一个指示器指向其父结点
typedef struct PTNode{ ElemType data; int parent; // 存储父结点在数组中的下标 }PTNode;
typedef struct{ PTNode nodes[MAX_SIZE]; // 结点数组 int r,n; // 根的位置和结点数目 }PTree;
2. 孩子表示法
把每个结点的孩子结点排列起来,以单链表作存储结构;n个头指针再组成一个线性表,放在一个数组中
// 孩子结点 typedef struct CTNode{ int child; // 结点在数组中的下标 struct CTNode *next; // 指向兄弟结点 }*ChildPtr; // 表头结点 typedef struct{ ElemType data; // 存放数据 ChildPtr firstchild; // 指向第一个孩子结点 }CTBox; // 树结构 typedef struct{ CTBox nodes[MAX_SIZE]; int r,n; // 根的位置和结点数目 }
3. 孩子兄弟表示法
任意一棵树,它的结点的第一个孩子若存在则唯一,右兄弟同理
typedef struct CSNode{ ElemType data; struct CSNode *firstchild,rightsib; }CSNode,*CSTree;
二叉树(Binary Tree)
二叉树的递归定义为:二叉树是一棵空树,或者是一棵由一个根结点和两棵互不相交的,分别称作根的左子树和右子树组成的非空树;左子树和右子树又同样都是二叉树**(结点的度不大于2)**
种类
1. 斜树
所有结点都只有左子树(左斜树)或右子树(右斜树),这不就是线性表吗?!
2. 满二叉树
所有结点都有左子树和右子树,并且叶子结点在同一层上
3. 完全二叉树
一棵深度为k的有n个结点的 二叉树 ,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与 满二叉树 中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树
二叉树性质
- 第i层最多有 2^(i-1)个结点
- 深度为k的二叉树最多有2^k - 1个结点
- 具有n个结点的完全二叉树深度为
floor(log2(n))+1 - 终端结点数为n0,度为2的结点数为n2,则n0 = n2 + 1
- 对于一棵有n个结点的完全二叉树,对任一结点i
- i = 1, 则结点i是二叉树的根
- i > 1, 则其双亲是结点
floor(i/2) - 2i > n, 则结点i无左孩子,否则左孩子是结点2i
- 2i + 1 > n,则结点无右孩子,否则右孩子是2i + 1
二叉树的创建
// 创建结构体存储节点 typedef struct BiTNode{ ElemType data; struct Node *lchild; struct Node *rchild; }BiTNode, *BiTree;
// 按照前序输入二叉树中结点的值 // #表示空,构建二叉链表表示二叉树 void CreateBiTree(BiTree *T){ ElemType ch; scanf("%c",&ch); if(ch == ‘#’) *T = NULL; else{ *T = (BiTree)malloc(sizeof(BiTNode)); *T -> data = ch; CreateBiTree(&(*T) -> lchild); CreateBiTree(&(*T) -> rchild); } }
二叉树的遍历
二叉树的遍历是指从根结点出发,按照某种次序依次访问二叉树中所有结点,使每个结点被访问一次且仅被访问一次
先序遍历(深度优先)
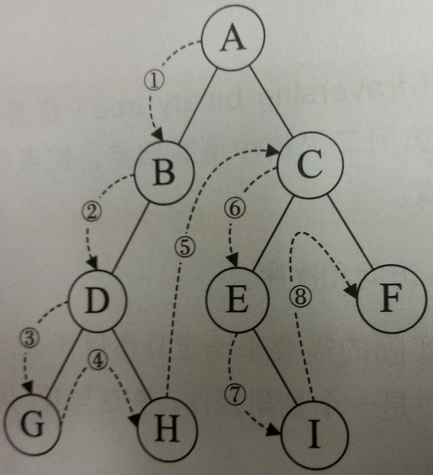
void DLR(struct Node* bt){ //根-左-右 if(bt == NULL) return; printf("%d",bt->data); DLR(bt->lchild); DLR(bt->rchild); }
中序遍历
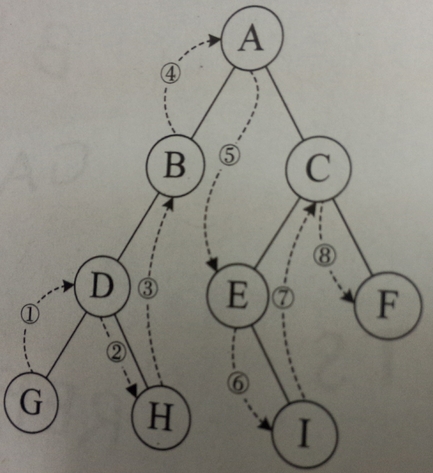
void LDR(struct Node* bt){ //左-根-右 if(bt == NULL) return; LDR(bt->lchild); printf("%d",bt->data); LDR(bt->rchild); }
后序遍历
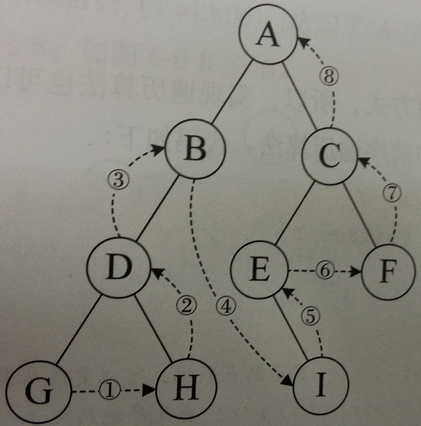
void LRD(struct Node* bt){ //左-右-根 if(bt == NULL) return; LRD(bt->lchild); LRD(bt->rchild); printf("%d",bt->data); }
层序遍历(广度优先)
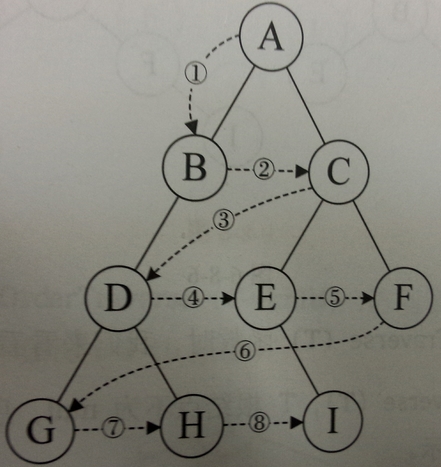

// 声明队列
Queue q;
// 将根节点加入队列
q.push(root);
//遍历队列中的每个结点
while(!q.empty()){
Node cur = q.front();
q.pop();
// 记录当前节点值
list.add(cur.val);
// 将左右孩子放入队列
q.push(cur.left);
q.push(cur.right);
}
线段树(二叉搜索树)
将一个区间分成两个子区间,再将每个子区间分成两个区间,直至只有一个元素为止
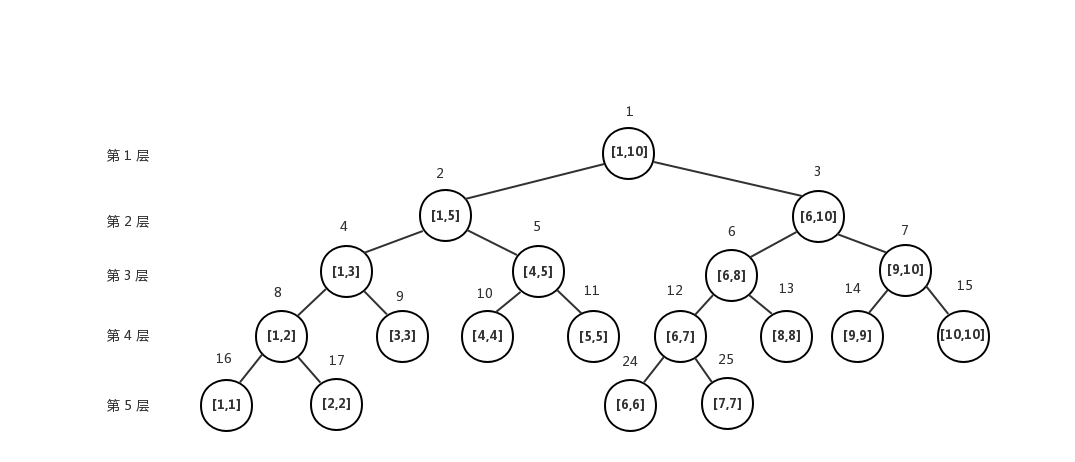
struct node{
int sum;
int lazy;//懒标记
}tree[MAX<<2];//MAX为这个线段树的大小,一般要开4倍
// first_node is 1
int left_node(int x){
return x*2;
}
int right_node(int x){
return x*2+1;
}
// 用子节点更新父节点数字
void push_up(int node){
tree[node].sum = tree[left_node(node)].sum + tree[right_node(node)].sum;
}
Build_tree
void build(int node,int start,int end){ if(start == end){ // 叶子节点 tree[node].sum = arr[start]; return; } int mid = (start + end)/2; build(left_node(node),start,mid); build(right_node(node),mid+1,end); push_up(node); return; }
区间修改,区间查询
引入懒标记将时间复杂度从O(nlogn)降低为O(logn)
// 修改节点 node -> (start,end) 的懒惰标记
void free(int node,int start,int end,int k){
tree[node].lazy += k; // 更改懒惰标记数值
tree[node].sum += k*(end-start+1); // 区间修改数值
return;
}
// 下传懒标记
void push_down(int node,int start,int end){
int mid = (start+end)/2;
free(left_node(node),start,mid,tree[node].lazy);
free(right_node(node),mid+1,end,tree[node].lazy);
tree[node].lazy = 0; // 清除懒标记
return;
}
// 区间修改
void update(int node,int start,int end,int L,int R,int k){
if(L<=start && end<=R){ // 维护的区间在修改区间内
//先修改该区间的lazy并更新相应数值
free(node,start,end,k);
return;
}
//这个区间维护的区间不在需要区间内(顺便下传懒标记)
push_down(node , start,end);
int mid = (start + end) / 2;
if(L <= mid){
update(left_node(node),start,mid,L,R,k);
}
if(R > mid){
update(right_node(node),mid+1,end,L,R,k);
}
push_up(node); // 更新父节点node
return;
}
// 区间查询
int query(int node,int start,int end,int L,int R){
int sum = 0;
//如果这个区间完全在查找区间内直接返回数值
if(L<=start && end <= R){
return tree[node].sum;
}
int mid = (start + end) / 2;
//顺便释放一下这个点的懒标记
push_down(node,start,end);
if(L<=mid){
sum+=query(left_node(node),start,mid,L,R);
}
if(R>mid){
sum+=query(right_node(node),mid+1,end,L,R);
}
return sum;
}
二叉排序树(Binary sort tree,BST)
从root开始,若小于当前结点走左,大于当前结点走右,遇到空结点停下
性质
左右两个子树都是一棵二叉排序树
左子树<根节点<右子树
二叉排序树的查找
比较关键字与根节点,若比根节点小,递归查找左子树,若比根节点大,递归查找右子树
/**
* 递归查找二叉排序树 T 中是否存在 key
* 指针 f 指向 T 的 双亲,其初始调用值为NULL
* 若查找成功,则指针 p 指向该数据元素结点,并返回TRUE
* 若查找不成功, 则指针 p 指向查找路径上访问的最后一个结点并返 回FALSE
*/
int SearchBST(struct node *t,int key,struct node *f,struct node **p){
if(!t){ // 查找不成功
*p = f;
return false;
}else if(key == t->data){
*p = t;
return true;
}else if(key < t->data){
return SearchBST(t->lchild,key,t,p);
}else{
return SearchBST(t->rchild,key,t,p);
}
}
二叉排序树的插入
调用SearchBST查询是否有要插入的关键字。若p为空,则插入关键字赋值给该结点;若小于结点p的data,则插入关键字作为p的左子树,反之插入右子树
int InsertBST(struct node **t,int key){
struct node *p,*s;
if(!SearchBST(*t,key,NULL,&p)){ //没找到key
s = new node;
s->data = key;
s->lchild = s->rchild = NULL;
if(!p)
*t = s; //插入s为新的根节点
else if(key<p->data)
p->lchild = s; //插入s为左孩子
else
p->rchild = s; //插入s为右孩子
return true;
}else
return false;
}
二叉排序树的删除
//从二叉排序树中删除结点p,并重接它的左右子树 int Delete(struct node **p){ struct node *q,*s; if((*p)->rchild == NULL){ //右子树空,只需重接左子树 q = *p; *p = (*p)->lchild; free(q); }else if((*p)->lchild == NULL){ //左子树空 q = *p; *p = (*p)->rchild; free(q); }else{ // 左右子树都不空 q = *p; s = (*p)->lchild; while(s->rchild){ //向右到尽头,找左边最大的数 q = s; s = s->rchild; } (*p)->data = s->data; //s指向被删除结点的前驱 if(q!=*p) q->rchild = s->lchild; //重接q右子树 else q->lchild = s->lchild; //重接q左子树 free(s); } return true; }
/**
* 二叉排序树的删除
* 当二叉排序树中存在关键字等于 key 的数据元素时,删除该数据元素 并返回TRUE
*/
int DeleteBST(struct node **t,int key){
if(!*t) // 不存在关键字等于 key 的元素
return false;
else{
if(key == (*t)->data)
return Delete(t);
else if (key < (*t)->data)
return DeleteBST(&(*t)->lchild, key);
else
return DeleteBST(&(*t)->rchild, key);
}
}
平衡树(Balanced Binary Tree)
性质
空树或所有结点平衡因子的绝对值不超过1
平衡因子:左子树与右子树的高度(深度)差(BF,Balance Factor)
左右两个子树都是一棵平衡二叉树
左子树<根节点<右子树
树状数组
t[x]保存以x为根的子树中叶节点值的和
t[x]节点的长度等于lowbit(x)
t[x]节点的父节点为t[x+lowbit(x)]
整棵树的深度为log2(n)+1
// 初始化,利用add函数初始化,时间复杂度O(nlogn)
void init_add(int length){
for(int i = 1;i <= length;i++)
add(i,a[i]);
}
// 初始化,利用初始化,时间复杂度O(n)
void init_preSum(int length){
int preSum[MAX];
for(int i = 1;i <= length;i++){
preSum[i] = preSum[i-1]+a[i] //计算前缀和
t[i] = preSum[i] - preSum[i&(i-1)];
}
}
// 单点修改
void add(int x, int k){
for(;x<=n;x+=x&-x) t[x]+=k;
}
// 查询前缀和
int ask(int x){
int ans = 0;
for(;x;x-=x&-x) ans+=t[x];
return ans;
}
// 单点修改,单点查询
add(x,k);
ask(x) - ask(x-1);
// 单点修改,区间查询
add(x,k);
ask(r) - ask(l-1);
// 区间修改,单点查询(hard)
add(l,d);add(r+1,-d);
ask(x);
// 区间修改,区间查询
int t1[max],t2[max];
void add1(int x, int k){
for(;x<=n;x+=x&-x) t1[x]+=k;
}
int ask1(int x){
int ans = 0;
for(;x;x-=x&-x) ans+=t1[x];
return ans;
}
void add2(int x, int k){
for(;x<=n;x+=x&-x) t2[x]+=k;
}
int ask2(int x){
int ans = 0;
for(;x;x-=x&-x) ans+=t2[x];
return ans;
}
add1(l,d);add1(r+1,-d);add2(l,l*d);add2(r+1,(r+1)*d);
(sum[r]+(r+1)*ask1(r)-ask2(r))-(sum[l-1]+l*ask1(l-1))
lowbit运算
lowbit(n) = n&(~n+1) = n&-n 非负整数n在二进制表示下最低位1及其后面的0构成的数值
差分数组



引入差分数组,一般用于区间修改,只需add(l,d) add(r+1,-d),即可实现[l,r]+d
// 区间修改,单点查询
[l,r]+d add(l,d) add(r+1,-d)
查询a[x] ans = ask[x]
// 差分数组的第n项的前缀和为a[n]
搜索
深度优先搜索(dfs)
对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次
void dfs(int step)
{
判断边界
尝试每一种可能for(i=1;i<=n;i++)
{
继续下一步 dfs(step+1)
}
return;
}
广度有先搜索(bfs)
一层一层进行扩展,每发现一个点便把一个点加入队列中
// 定义一个结构体用于存放节点
struct node
{
int x; // 横坐标
int y; // 纵坐标
int f; // 父亲在队列中的编号
int s; // 步数
};
// 定义一个用于表示走的方向的数组
int next[4][2] = {{0,1},//向右走
{1,0},//向下走
{0,-1},//向左走
{-1,0}//向上走};
// 核心
while(head < tail) // 队列不为空时循环
{
// 枚举四个方向
for(k = 0;k <= 3;k++)
{
// 计算下一个点的坐标
tx = que[head].x + next[k][0];
ty = que[head].y + next[k][1];
// 判断是否越界
if(tx < 1 || tx > n || ty < 1 || ty > m)
continue;
// 判断是否是障碍物或者已在队列中
if(a[tx][ty] == 0 && book[tx][ty] == 0)
{
// 把这个点标记已走过
// BFS每个点只入队一次
book[tx][ty] = 1;
// 插入新的点到队列中
que[tail].x = tx;
que[tail].y = ty;
que[tail].f = head;
que[tail].s = que[head].s + 1;
tail++;
}
// 如果找到目标点了,停止扩展
if(tx == p && ty ==q)
{
flag = 1;
break;
}
}
if(flag == 1)
break;
head++; // 一个点扩展结束后,head++对下一个点进行扩展
}
图 - Graph
图是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为G(V,E),其中G表示一个图,V为顶点的集合,E为边的集合
术语
- 顶点:图中的数据元素称为顶点
- 度 - degree:顶点v的度是和v相关联的边的数目,记作TD(v)
- 入度 - InDegree:以v为头的弧的数目称为v的入度,记作ID(V)
- 出度 - OutDegree:以v为尾的弧的数目称为v的出度,记作OD(V)
- 无向边 - edge:顶点v1到v2之间的边没有方向,用无序偶对(v1,v2)表示
- 有向边 - 弧(arc):从v1到v2的边用<v1,v2>表示,v1为弧尾,v2为弧头
- 权 - weight:与弧或边相关的数叫做权
- 回路 - 环(cycle):第一个顶点到最后一个顶点相同的路径
图的存储结构
邻接矩阵 - Adjacency Matrix
一个一维数组存储顶点信息,一个二维数组(称邻接矩阵)存储图中的边或弧的信息

typedef struct{
VertexType vexs[MAXSIZE]; //顶点表
EdgeType arc[MAXSIZE][MAXSIZE]; //邻接矩阵,边表
int numVertexes,numEdges; //顶点数和边数
}
邻接表 - Adjacency List
顶点用一个一维数组存储,且每个顶点需要存储指向第一个邻接点的指针,每个顶点的所有邻接点构成一个线性表

// 边表结点
typedef struct EdgeNode{
int adjvex; //邻接点域,存储下标
EdgeType weight; //存储权值
struct EdgeNode *next; //指向下一个邻接点
}EdgeNode;
// 顶点表结点
typedef struct VertexNode{
VertexType data; //顶点域
EdgeNode *firstedge; //边表头指针
}VertexNode,AdjList[MAXSIZE];
typedef struct{
AdjList adjList;
int numVertexes,numEdges;
}GraphAdjList;
十字链表 - Orthogonal List

邻接多重表
图的遍历
从图中某一顶点出发访遍图中其余顶点,且使每个顶点仅被访问一次,这一过程就叫图的遍历(Traversing Graph)
深度优先遍历 - Depth First Search
Boolean visited[MAX] //访问标志的数组 void dfs(MGraph G,int i){ visited[i] = true; printf("%c",G.vexs[i]); for(int j = 0;j < G.numVertexes;j++) if(G.arc[i][j] == 1 && !visited[j]) dfs(G,j); // 对访问的邻接顶点递归调用 }
void dfsTraverse(MGraph G){
for(int i = 0;i < G.numVertexes;i++)
visited[i] = false // 初始所有顶点状态都是未访问
for(int i = 0;i < G.numVertexes;i++)
//对未访问过的顶点调用dfs,若是连通图只执行一次
if(!visited[i])
dfs(G,i);
}
广度优先遍历 - Breadth First Search
void bfsTraverse(MGraph G){ int i,j; Queque Q; for(i = 0;i < G.numVertexes;i++) visited[i] = false; InitQueue(&Q); // 对每一顶点做循环 for(i = 0;i < G.numVertexes;i++){ if(!visited[i]){ visited[i] = true; printf("%c",G.vexs[i]); EnQueue(&Q,i); // 将此顶点入队 while(!QueueEmpty(Q)){ DeQueue(&Q,&i); for(j = 0;j < G.numVertexes;j++){ if(G.arc[i][j] == 1&&!visited[j]){ visited[j] = true; printf("%c",G.vexs[j]); EnQueue(&Q,j); } } } } } }
最小生成树 - Minimum Cost Spanning Tree
构造连通网的最小代价生成树称为最小生成树
普里姆(Prim)算法
从已加入最小生成树的顶点的边中,找到一条代价最小的边(权值最小,且另一顶点未加入最小生成树)并入最小生成树的边,同时另一顶点并入最小生成树的顶点中,直到所有顶点加入最小生成树为止

void MiniSpanTree_Prim(MGraph G){
int min,i,j,k;
int adjvex[MAXVEX]; //保存相关顶点下标
int lowcast[MAXVEX]; //保存相关顶点间边的权值
lowcost[0] = 0; //初始化第一个权值为0,即v0加入生成树
adjvex[0] = 0; //假定第一个顶点为v0
for(i = 1;i < G.numVertexes;i++){
// 将v0顶点与之有边的权值存入数组
lowcost[i] = G.arc[0][i];
adjvex[i] = 0;
}
for(i = 1;i < G.numVertexes;i++){
min = INFINITY; //初始化最小值为正无穷
//j为顶点下标的循环变量,k用于存储最小权值的顶点下标
j = 1;k = 0;
while(j < G.numVertexes){ //循环遍历全部顶点
if(lowcost[j]!=0 && lowcost[j]<min){
min = lowcost[j]; //让当前权值为min
k = j; //最小值下标存入k
}
j++;
}
//打印当前顶点边中权值的最小边
printf("(%d,%d)",adjvex[k],[k]);
lowcost[k] = 0; //当前顶点权值设为0,表明完成任务
for(j = 1;j < G.numVertexes;j++){
//若下标为k顶点各边权值小于此前这些顶点未被加入生成树的权值
if(lowcost[j]!=0 && G.arc[k][j]<lowcost[j]){
lowcost[j] = G.arc[k][j]; //较小权值存入lowcost
adjvex[j] = k;
}
}
}
}
克鲁斯卡尔(Kruskal)算法
将连通网中所有的边按照权值大小做升序排序,从权值最小的边开始选择,只要此边不和已选择的边一起构成环路,就可以选择它组成最小生成树
// 对边集数组Edge结构的定义
typedef struct{
int begin;
int end;
int weight;
}Edge;
void MiniSpanTree_Kruskal(MGraph G){
int i,n,m;
Edge edges[MAXEDGE]; //定义边集数组
int parent[MAXVEX]; //判断边与边是否形成环路
/*此处省略邻接矩阵转化为edges且按从小到大排序的代码*/
for(i = 0;i < G.numVertexes;i++){
parent[i] = 0;
}
for(i = 0;i < G.numEdges;i++){ //遍历每一条边
n = Find(parent,edges[i].begin);
m = Find(parent,edges[i].end);
if(n!=m){ //m不等于n,说明此边没有与现有的生成树形成回路
//将此边的结尾顶点放入下标为起点的parent中
//表示此顶点已经在生成树集合中
parent[n] = m;
printf("(%d %d) %d",edges[i].begin,edges[i].end,edges[i].weight);
}
}
}
//查找连线顶点的尾部下标
int Find(int *parent, int f){
while(parent[f] > 0){
f = parent[f];
}
return f;
}
最短路径
两顶点之间经过的边上权值之和最少的路径 ####Floyd - Warshall(弗洛伊德算法) 单独一条边的路径也不一定是最佳路径。 从任意一条单边路径开始。所有两点之间的距离是边的权的和,(如果两点之间没有边相连, 则为无穷大)。 从第一个顶点开始,依次将每个顶点作为媒介 k,然后对于每一对顶点 u 和 v ,查看其是否存在一条经过 k 的,距离比已知路径更短的路径,如果存在则更新它
for(k = 1;k <= n;k++)
for(i = 1;i <= n; i++)
for(j = 1;j <= n;j++)
if(e[i][j]>e[i][k] + e[k][j])
e[i][j]=e[i][k] + e[k][j];
Dijkstra算法
每次找到离源点最近的一个顶点,以该顶点为中心进行扩展,最终得到源点到其他所有点的最短路径
for(i = 1;i <= n-1;i++)
{
// 找到离1号最近的顶点
min = inf;
for(j = 1;j <= n;j++)
{
if(book[j]==0 && dis[j] < min)
{
min = dis[j];
u = j;
}
}
book[u] = 1;
for(v = 1;v <= n;v++)
{
if(e[u][v] < inf)
{
if(dis[v] > dis[u] + e[u][v])
dis[v] = dis[u] +
e[u][v]; } } }
Bellman-Ford —— 解决负权边
对所有边进行n-1次松弛操作
// 循环n-1次,最短路径上最多有n-1条边
for(k = 1;k <= n-1;k++)
for(i = 1;i <= m;i++) // 枚举每一条边
if(dis[v[i]] > dis[u[i]] + w[i])
dis[v[i]] = dis[u[i]] + w[i];
// dis数组记录源点到各顶点的最短距离
// 检测负权回路
// 若n-1次松弛后仍然可以继续松弛,则必然存在负权回路
flag = 0;
for(i = 1;i <= m;i++)
if(dis[v[i]] > dis[u[i]] + w[i])
flag = 1;
if(flag == 1)
printf("存在负权回路");
// 两种优化算法
// 第一种,新一轮松弛中dis数组不变即可结束
// 第二种,每次仅对最短路估计值发生变化了的顶点进行松弛
邻接表 + Bellman-Ford
初始时将源点加入队列,每次从队首取出一个顶点,并对与其相邻的所有顶点进行松弛尝试,若某个相邻顶点松弛成功,且这个相邻的顶点不在队列中(head和tail之间),则将它加入队列。对当前顶点处理完毕后立即出队,并对下一个点进行上述操作,直至队列为空。
// 初始化dis数组,1号顶点到其余顶点的初始路程
for(i = 1;i <= n;i++)
dis[i] = inf;
dis[1] = 0
// 初始化book数组,刚开始为0,都不在队列中
for(i = 1;i <= n;i++) book[i] = 0;
// 初始化first数组为-1,表示无边
for(i = 1;i <= n;i++) first[i] = -1;
for(i = 1;i <= m;i++)
{
// 读入边
scanf("%d %d %d",&u[i],&v[i],&w[i]);
// 建立邻接表
next[i] = first[u[i]];
first[u[i]] = i;
}
// 1号顶点入队
que[tail] = 1;
tail++;
book[1] = 1;
while(head < tail) // 队列不为空时循环
{
k = first[que[head]];
while(k != -1) // 扫描当前顶点的所有边
{
if(dis[v[k]] > dis[u[k]] + w[k])
{
dis[v[k]] = dis[u[k]] + w[k];
if(book[v[k]] == 0)
{
// 入队操作
que[tail] = v[k];
tail++;
book[v[k]] = 1;
}
}
k = next[k];
}
// 出队
book[que[head]] = 0;
head++;
}
拓扑排序
拓扑序列
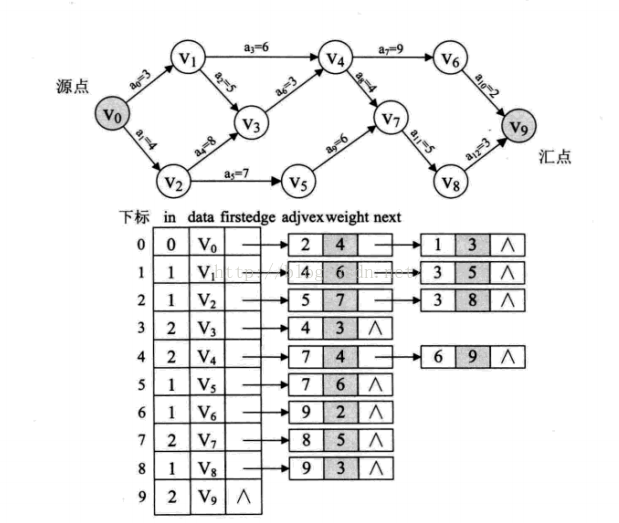
在一个表示过程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,称为AOV网(Activity On Vertex Network)
设 G=(V,E) 是一个具有n个顶点的有向图,V中顶点序列v1,v2,v3,…,vn,满足若从顶点vi到vj有一条路径,则在顶点序列中顶点vi必在顶点vj之前,则我们称这样的顶点序列为一个拓扑序列
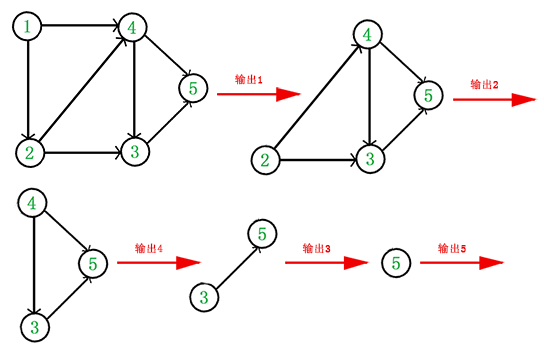
拓扑排序,实质为对一个有向图构造拓扑序列的过程 ####拓扑排序算法 从AOV网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或AOV网中不存在入度为0的顶点为止
trpedef struct EdgeNode{ //边表结点
int adjvex; //邻接点域,存储该顶点对应的下标
int weight; //存储权值
struct EdgeNode *next; //链域,指向下一个邻接点
}EdgeNode;
typedef struct VertexNode{ //顶点表结点
int in; //顶点入度
int data; //顶点域,存储定点信息
EdgeNode *firstedge; //边表头指针
}VertexNode,AdjList[MAXVEX];
typedef struct{
AdjList adjList;
int numVertexes,numEdges;//图中当前顶点数和边数
}graphAdjList,*GraphAdjList;

在算法中,还需要辅助数据结构——栈,用来存储处理过程中入度为0的顶点,目的是为了避免每个查找时都要去遍历顶点表找有无入度为0的顶点
Status TopologicalSort(GraphAdjList GL){
EdgeNode *e;
int i,k,gettop;
int top = 0; //用于栈指针下标
int count = 0; //用于统计输出顶点的个数
int *stack; //建栈存储入度为0的顶点
stack = (int *)malloc(GL->numVertexes*sizeof(int));
for(i = 0; i < GL->numVertexes;i++){
if(GL->adjList[i].in == 0){
stack[top++] = i; //入度为0的顶点入栈
}
}
while(top!=0){
gettop = stack[top--]; //出栈
printf("%d -> ",GL->adjList[gettop].data);//打印此顶点
count++; //统计输出顶点数
//对此顶点的边表遍历
for(e=GL->adjList[gettop].firstedge;e;e=e->next){
k = e->adjvex;
if(!(--GL->adjList[k].in))
stack[++top] = k;
}
}
if(count < GL->numVertexes) //若count小于顶点数,说明存在环
return ERROR
else
return OK
}
关键路径
在一个表示工程的带权有向图中,用顶点表示事件,用有向边表示活动,用边上的权值表示活动的持续时间,这种有向图的边表示活动的网,称之为AOE网(Activity On Edge Network)

路径上各个活动所持续时间之和称为路径长度,从源点到汇点具有最大长度的路径叫做关键路径,在关键路径上的活动叫关键活动
关键路径算法原理
定义如下几个参数
- 事件的最早发生时间 etv (earliest time of vertex):即顶点vk的最早发生时间
- 事件的最晚发生时间 ltv (lastest time of vertex):即顶点vk的最晚发生时间
- 活动的最早开始时间 ete (earliest time of edge):即弧ak的最早发生时间
- 活动的最晚开始时间 lte (latesest time of edge):即弧ak的最晚发生时间
如果最早开始时间和最晚开始时间相等,则是关键路径 ####关键路径算法
int *etv,*ltv; //事件最早发生时间和最迟发生时间数组 int *stack2; //用于存储拓扑序列的栈 int top2; //用于stack2的指针
// 拓扑排序,用于关键路径计算 Status TopologicalSort(GraphAdjList GL){ EdgeNode *e; int i,k,gettop; int top = 0; // 用于栈指针下标 int count = 0; // 用于统计输出顶点个数 int *stack; // 建栈将入度为0的顶点入栈 stack = (int *)malloc(GL->numVertexes * sizeof(int)); for(i = 0;i < GL->numVertexes;i++){ if(0 == GL->adjList[i].in) stack[++top] = i; } top2 = 0; etv = (int )malloc(GL->numVertexessizeof(int)); for(i = 0;i < GL->numVertexes;i++){ etv[i] = 0 } stack2 = (int )malloc(GL->numVertexessizeof(int));
while(top!=0){ gettop = stack[top--]; count++; stack2[++top2] = gettop; //将弹出的顶点序号压入拓扑序列的栈 for(e = GL->adjList[gettop].firstedge;e;e=e->next){ k = e->adjvex; if(!(--GL->adjList[k].in)){ stack[++top] = k; } //求各顶点事件最早发生的时间值 if((etv[gettop]+e->weight)>etv[k]){ etv[k] = etv[gettop] + e->weight; } } } if(count<GL->numVertexes) return ERROR; else return OK;}
// 求关键路径,GL为有向网,输出GL的各项关键活动 void CriticalPath(GraphAdjList GL){ EdgeNode *e; int i,gettop,k,j; int ete,lte; //声明活动最早发生时间和最迟发生时间 TopologicalSort(GL); //求拓扑序列,计算etv和stack2 ltv = (int )malloc(GL->numVertexessizeof(int)); for(i = 0;i < GL->numVertexes;i++) ltv[i] = etv[GL->numVertexes-1] //初始化ltv // 计算ltv whilt(top2!=0){ gettop = stack2[top2–]; //拓扑序列出栈 // 求各顶点事件的最迟发生时间ltv值 for(e = GL->adjList[gettop].firstedge;e;e=e->next){ k = e->adjvex; if(ltv[k]-e->weight < lev[gettop]){ ltv[gettop] = ltv[k] - e->weight; } } } for(j = 0;j < GL->numVertexes;j++){ for(e = GL->adjList[j].firstedge;e;e=e->next){ k = e->adjvex; ete = etv[j]; //活动最早发生时间 lte = ltv[k] - e->weight;//活动最迟发生时间 if(ete = lte) //两者相等即在关键路径上 printf("<v%d,v%d> length: %d,",GL->adjList[j].data,GL->adjList[k].data,e->weight); } } }
查找 - Search
根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)
顺序表查找
// 顺序查找,a为数组,n为要查找的数组个数,key为要查找的关键字 int Sequential_Search(int *a,int n,int key){ int i; for(i = 1;i <= n;i++){ if(a[i] == key){ return i; } } return 0; }
顺序表查找优化
int Sequential_Search2(int *a,int n,int key){ int i; a[0] = key; //设置a[0]为关键字值,称为“哨兵” i = n; //循环从尾部开始 while(a[i] != key){ i–; } return i; //返回0说明查找失败 }
有序表查找
对已经排序的线性表进行查找
二分查找
在有序表中,取中间值为比较对象,若给定值与中间记录的关键字相等则查找成功;若给定值小于中间记录,则在中间记录的左半区继续查找;若给定值大于中间记录,则在中间记录的右半区继续查找
int Binary_Search(int *a,int n,int key){
int low,high,mid;
low = 1; //定义最低下标为首位
high = n; //定义最高下标为末位
while(low<=high){
mid = (high+low)/2; //折半
if(key < a[mid]){
high = mid-1;
}else if(key > a[mid]){
low = mid + 1;
}else{
return mid;
}
}
return 0;
}
插值查找 - Interpolation Search
根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法
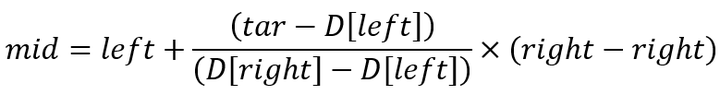
mid = low+(high-low)*(key-a[low])/(a[high]-a[low]);
斐波那契查找 - Fibonacci Search
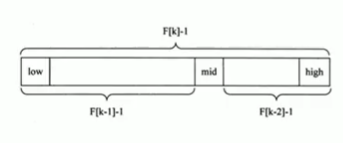
int Fibonacci_Search(int *a,int n,int key){
int low,high,mid,i,k;
low = 1;
high = n;
k = 0;
while(n > F[k] - 1) //计算n位于斐波那契数列的位置
k++;
for(i = n;i < F[k]-1;i++) //将不满的数值补全
a[i] = a[n];
while(low <= high){
mid = low+F[k-1]-1;
if(key < a[mid]){
high = mid-1;
k = k-1;
}else if(key > a[mid]){
low = mid+1;
k=k-2;
}else{
if(mid <= n)
return mid;
else
return n; //若mid>n说明是补全数值,返回n
}
}
return 0;
}
线性表索引查找
稠密索引
稠密索引指,在线性索引中,将数据集中的每个记录对应一个索引项
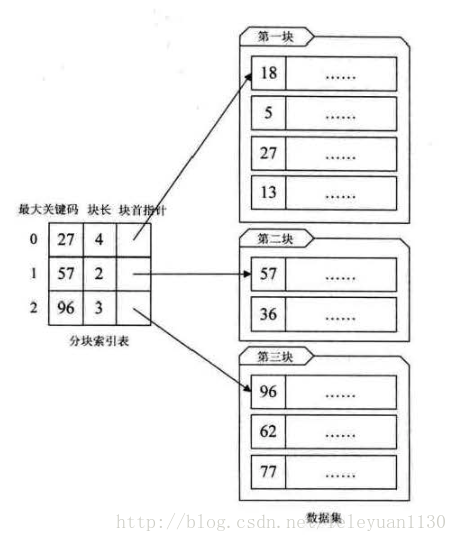
分块索引
二叉排序树 - Binary Sort Tree
又称二叉搜索树(Binary Search Tree),满足如下性质:
- 若左子树非空,则左子树上所有结点的值均小于根节点的值
- 若右子树非空,则右子树上所有结点的值均大于根节点的值
- 左右子树本身又是一颗二叉排序树
二叉排序树查找操作
// 二叉树的二叉链表结点结构定义 typedef struct BiTNode{ int data; struct BiTNode *lchild,*rchild; }BiTNode,*BiTree;
// 递归查找二叉排序树T中是否存在key // f指向T的双亲,初始为NULL // 查找成功则指针p指向该数据元素的结点,返回TRUE // 查找失败则指针p指向查找路径的最后一个结点,返回FALSE Status SearchBST(BiTree T,int key,BiTree f,BiTree *p){ if(!T){ *p = f; return FALSE; }else if(key == T->data){ *p = T; return TRUE; }else if(key < T->data){ return SearchBST(T->lchild,key,T,p); }else if(key > T->data){ return SearchBST(T->rchild,key,T,p); } }
二叉排序树插入操作
// 当二叉排序树T中不存在关键字等于key的数据元素时 // 插入key并返回TRUE Status InsertBST(BiTree *T,int key){ BiTree p,s; if(!SearchBST(*T,key,NULL,&p)){ s = (BiTree)malloc(sizeof(BiTNode)); s->data = key; s->lchild = s->rchild = NULL; if(!p) *T = s; //插入s为新的根节点 else if(key < p->data) p->lchild = s; //插入s为左孩子 else p->rchild = s; //插入s为右孩子 return TRUE; }else{ return FALSE; } }
二叉排序树删除操作
若结点为叶子结点,直接删除即可;若结点只有左子树或右子树,则删除结点后,将左子树或右子树整个移动到删除结点的位置;若结点有左子树和右子树,则找到需要删除的结点p的直接前驱(小于p的最大值)或者直接后继(大于p的最小值)来替换p
// 若二叉排序树中存在关键字等于key的数据元素时,则删除该数据元素结点 Status DeleteBST(BiTree *T, int key){ if(!*T) // 不存在关键字等于key的数据元素 return FALSE; else{ if(key == (*T)->data) return Delete(T); else if(key < (*T)->data) return DeleteBST(&(*T)->lchild,key); else if(key > (*T)->data) return DeleteBST(&(*T)->rchild,key); } }
// 从二叉排序树中删除结点p,并重接它的左右子树 Status Delete(BiTree *p){ BiTree q,s; if((*p)->rchild == NULL){ // 右子树为空 q = *p; *p = (*p)->lchild; free(q); }else if((*p)->lchild == NULL){ // 左子树为空 q = *p; *p = (*p)->rchild; free(q); }else{ //左右子树都不为空 q = *p; s = (*p)->lchild; while(s->rchild){ // 转左,向右到尽头 q = s; s = s->rchild; } (*p)->data = s->data; //s指向被删结点的直接前驱 if(q!=*p) q->rchild = s->lchild; //重接q的右子树 else q->lchild = s->lchild; //重接q的左子树 } return TRUE; }
平衡二叉树
平衡二叉树是一种二叉排序树,其中每一个结点的左子树和右子树的高度差至多等于1
将二叉树上结点的左子树深度减右子树深度的值称为平衡因子BF(Balance Factor)
平衡二叉树实现
// 二叉树的二叉链表结点结构定义 typedef struct BiTNode{ int data; int bf; //结点的平衡因子 struct BiTNode *lchild,*rchild; }BiTNode,*BiTree;
// 对以p为根的二叉排序树作右旋处理
// 处理后p指向新的树根结点,即旋转处理之前的左子树的根节点
void R_Rotate(BiTree *p){
BiTree L;
L = (*p)->lchild; // L指向p的左子树根节点
(*p)->lchild = L->rchild; // L的右子树为p的左子树
L->rchild = (*p);
*p = L; // p指向新的根节点
}
// 对以p为根的二叉排序树作左旋处理
// 处理后p指向新的树根结点,即旋转处理之前的右子树的根节点
void R_Rotate(BiTree *p){
BiTree R;
R = (*p)->rchild; // R指向p的右子树根节点
(*p)->rchild = R->lchild; // R的左子树为p的右子树
R->lchild = (*p);
*p = R; // p指向新的根节点
}
#define LH +1 //左高
#define EH +1 //等高
#define RH +1 //右高
// 对以指针T所指结点为根的二叉树作左平衡旋转处理
// 本算法结束时,指针T指向新的根节点
void LeftBalance(BiTree *T){
BiTree L,Lr;
L = (*T)->lchild; // L指向T的左子树根节点
switch(L->bf){ // 检查T的左子树平衡度
// 新节点插入在T的左孩子的左子树上,作单右旋处理
case LH:
(*T)->bf = L->bf = EH;
R_Rotate(T);
break;
// 新节点插入在T的左孩子的右子树上,作双旋处理
case RH:
Lr = L->rchild; //Lr指向T左孩子的右子树根
switch(Lr->bf){ //修改T及其左孩子的平衡因子
case LH:
(*T)->bf = RH;
L->bf = EH;
break;
case EH:
(*T)->bf = L->bf = EH;
break;
case RH:
(*T)->bf = EH;
L->bf = LH;
break;
}
Lr->bf = EH;
L_Rotate(&(*T)->lchild); //对T的左子树作左旋
R_Rotate(T); //对T作右旋处理
}
}
// void RightBalance(BiTree *T);
// 若在平衡二叉排序树T中不存在和e有相同关键字的结点,
// 则插入值为e的结点并返回1,否则返回0
// 同时保持二叉排序树的平衡,布尔变量taller反应T长高与否
Status InsertAVL(BiTree *T,int e,Status *taller){
if(!*T){
*T = (BiTree)malloc(sizeof(BiTNode));
(*T)->data = e;
(*T)->lchild = (*T)->rchild = NULL;
(*T)->bf = EH;
*taller = TRUE;
}else{
// 树中已存在和e有相同关键字的结点则不再插入
if(e == (*T)->data){
*taller = FALSE;
return FALSE;
}
// 在T的左子树中进行搜索
if(e < (*T)->data){
if(!InsertAVL(&(*T)->lchild,e,taller))
return FALSE;
// 插入到T的左子树且左子树长高
if(taller){
//检查T的平衡度
switch((*T)->bf){
//原本左子树高,作平衡处理
case LH:
LeftBalance(T);
*taller = FALSE;
break;
//原本等高,现在左子树增高
case EH:
(*T)->bf = LH;
*taller = TRUE;
break;
//原本右高,现在登高
case RH:
(*T)->bf = EH;
*taller = FALSE;
break;
}
}
}else{
// 在T的右子树中进行搜索
if(!InsertAVL(&(*T)->rchild,e,taller))
return FALSE;
// 插入到T的右子树且右子树长高
if(taller){
//检查T的平衡度
switch((*T)->bf){
//原本左子树高,现在等高
case LH:
(*T)->bf = EH;
*taller = FALSE;
break;
//原本等高,现在右子树增高
case EH:
(*T)->bf = RH;
*taller = TRUE;
break;
//原本右高,现在作右平衡处理
case RH:
RightBalance(T);
*taller = FALSE;
break;
}
}
}
}
return TRUE;
}
多路查找树(muitl-way search tree)
多路查找树每个结点的孩子数可以多于两个,且每一个结点处可以存储多个元素
1. 2-3树
2-3树是这样一颗多路查找树:其中每个结点都具有两个孩子(我们称它为2结点)或三个孩子(我们称它为3结点)
一个2结点包含一个元素和两个孩子(或没有孩子),且与二叉排序树类似,左子树的元素小于该元素,右子树的元素大于该元素
一个3结点包含一小一大两个元素和三个孩子(或没有孩子),左子树包含小于较小元素的元素,右子树包含大于较大元素的元素
2. 2-3-4树
2-3树的扩展,包含了4结点的使用,一个4结点包含小中大三个元素和四个孩子(或没有孩子),左子树包含小于最小元素的元素,第二子树包含大于最小元素,小于第二元素的元素,第三子树包含大于第二元素,小于最大元素的元素,右子树包含大于最大元素的元素
3. B树
B树(B-tree)是一种平衡的多路查找树,结点最大的孩子数目称为B树的阶(order)
一个m阶B树有如下属性:
- 如果根结点不是叶结点,则至少有两棵子树
- 每一个非根的分支结点有k-1个元素和k个孩子,ceil(m/2)<= k <= m
- 每一个叶子结点有k-1个元素,ceil(m/2)<= k <= m
- 所有叶子结点位于同一层次
- 所有分支结点包含下列信息数据(n,A0,K1,A1,K2,A2…,Kn,An),其中Ki为关键字,且Ki<K(i+1);Ai为指向子树根节点的指针,且指针A(i-1)所指子树中所有结点的关键字均小于Ki,An所指子树中所有结点的关键字均大于Kn,n(ceil(m/2)-1<=n<=m-1)为关键字的个数(或n+1为子树的个数) ####4. B+树
- 有n棵子树的结点中包含有n个关键字
- 所有叶子结点包含全部关键字的信息,及指向含这些关键字记录的指针,叶子结点本身依关键字的大小自小而大链接
- 所有分支结点可以看成是索引,结点中仅含有其子树中的最大(或最小)关键字
哈希表
哈希表查找定义
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字对应一个存储位置f(key),f称为散列函数,又称Hash函数,采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表或Hash table
哈希函数的构造方法
- 计算简单
- 散列地址分布均匀
1. 直接定址法
取关键字的某个线性函数值为散列地址
f(key) = a*key+b (a,b为常数)
2. 数字分析法
使用关键字的一部分来计算散列存储位置
3. 平方取中法
适用于不知道关键字分布,而位数又不是很大的情况
4. 折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数不够可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作地址
如:关键字为9876543210,散列表表长为三位,我们将它分为四组987|654|321|0,将他们叠加求和987+654+321+0=1962,取后三位962为地址
若不能保证分布均匀,可以将987和321反转,再与654和0相加,得1566,取566为地址
5. 除留余数法
f(key) = key % p (p<=m)
散列表表长为m,通常p为小于等于表长(最接近m)的最小质数或不包含小于20质因子的合数
6. 随机数法
f(key) = random(key)
处理散列冲突的方法
1. 开放定址法
开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
// 线性探测法
// d = 1,2,3....m-1
f(key) = (f(key) + d) % m
// 二次探测法,为了不让关键字聚集在某一块区域
// d = 1,-1,2,-2.....q,-q (q<=m/2)
f(key) = (f(key) + d) % m
// 随机探测法
// d是一个随机数列
f(key) = (f(key) + d) % m
2. 再散列函数法
准备多个散列函数,当地址冲突时,换一个散列函数进行计算
3. 链地址法

以链表的形式存储数据
4. 公共溢出区法

散列表查找
#define SUCCESS 1 #define UNSUCCESS 0 #define HASHSIZE 12 #define NULLKEY -32768 typedef struct{ int *elem; //数据元素存储基址,动态分配数组 int count; //当前数据元素个数 }HashTable; int m = 0; //散列表表长
// 初始化散列表
Status InitHashTable(HashTable *H){
int i;
m = HASHSIZE;
H->count = m;
H->elem = (int *)malloc(m*sizeof(int));
for(i = 0;i < m;i++)
H->elem[i] = NULLKEY;
return OK;
}
// 散列函数
int Hash(int key){
return key%m; //除留余数法
}
//插入关键字进散列表
void InsertHash(HashTable *H,int key){
int addr = Hash(key); //求散列地址
while(H->elem[addr] != NULLKEY) //如果不为空则冲突
addr = (addr+1)%m; //开放定址法
H->elem[addr] = key; //插入操作
}
//散列表查找关键字
Status SearchHash(HashTable H,int key,int *addr){
*addr = Hash(key); //求散列地址
while(H.elem[addr] != key){ //如果不为空则冲突
*addr = (*addr+1)%m; //开放定址法
//如果循环回到原点
if(H.elem[*addr] == NULLKEY || *addr == Hash(key)){
return UNSUCCESS; //则说明关键字不存在
}
}
return SUCCESS;
}
Other
约瑟夫环
N个人围成一圈,第一个人从1开始报数,报M的将被杀掉,下一个人接着从1开始报。如此反复,最后剩下一个,求最后的胜利者。
1. 模拟
用链表的方法去模拟这个过程,N个人看作是N个链表节点,节点1指向节点2,节点2指向节点3,……,节点N-1指向节点N,节点N指向节点1,这样就形成了一个环。然后从节点1开始1、2、3……往下报数,每报到M,就把那个节点从环上删除。下一个节点接着从1开始报数。最终链表仅剩一个节点。它就是最终的胜利者。
时间复杂度O(nm)
2.公式法
- 递推公式
- f(N,M)=(f(N−1,M)+M)%N
- f ( N , M ) 表示,N个人报数,每报到M时杀掉那个人,最终胜利者的编号
- f ( N − 1 , M ) 表示,N-1个人报数,每报到M时杀掉那个人,最终胜利者的编号
计数质数
1. 枚举
若y是x的因数,则x/y也是x的因数,其中只需校验min{y,x/y}即可,若每次都校验较小数,不难发现较小数一定落在[2,sqrt(x)]中
class Solution {
public int countPrimes(int n) {
int ans = 0;
for (int i = 2; i < n; ++i) {
ans += isPrime(i) ? 1 : 0;
}
return ans;
}
public boolean isPrime(int x) {
for (int i = 2; i * i <= x; ++i) {
if (x % i == 0) {
return false;
}
}
return true;
}
}
2. 厄拉多塞筛法 - 埃氏筛
如果 x 是质数,那么大于 x 的 x 的倍数 2x,3x,… 一定不是质数,这里应从x*x开始标记,因为2x,3x,…这些数一定在x之前被其他数的倍数标记过了
设isPrime[i] 表示数 i 是不是质数,如果是质数则为 1,否则为 0。从小到大遍历每个数,如果这个数为质数,则将其所有的倍数都标记为合数(除了该质数本身),即 0
class Solution {
public int countPrimes(int n) {
int[] isPrime = new int[n];
Arrays.fill(isPrime, 1);
int ans = 0;
for (int i = 2; i < n; ++i) {
if (isPrime[i] == 1) {
ans += 1;
if ((long) i * i < n) {
for (int j = i * i; j < n; j += i) {
isPrime[j] = 0;
}
}
}
}
return ans;
}
}